ResMem Release
A user-ready version of ResMem is now available on PyPI! The model included in the package is designed to estimate the memorability of an input image but is not intended for feature space analysis. The model is optimized for accuracy by allowing the ResNet features to retrain. The model included in the resmem package has been dubbed “ResMemRetrain” for this reason. Statistically, the retrained model performs better than the model where ResNet is as-is, receiving a Spearman rank correlation of 0.64 on a held-out sample from both LaMem and MemCat. It also has an average squared loss of 0.009, which means that on average, the model predictions are off by 0.094, but more on that later.
If you’re just interested in using the model, the code is available on github. To install the model in Python 3, you can use pip.
pip install resmem
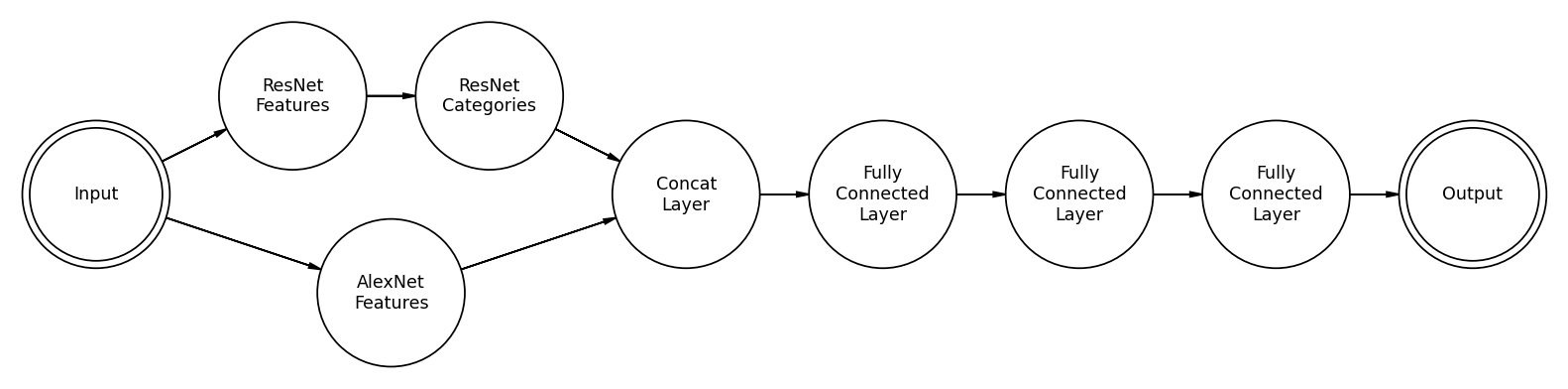
ResMem is a deep learning model built in PyTorch for estimating the memorability of an image. It uses the classic image classification architecture ResNet as a feature space and a Convolutional Neural Network feature space based on AlexNet. Then, using a series of linear transformations, estimations of memorability are generated from these features.
If you’re only using resmem to estimate image memorability, you can expect that most of your predictions will be more accurate than the figures mentioned earlier. However, it may be useful to know how the model behaves more broadly. This section is intended to elucidate this. ResMemRetrain, as tested on a random selection of images from LaMem1 and MemCat2, has an average “inaccuracy” of about ten percent as discussed earlier, but there are some mitigating factors.
The figure below shows two distributions of memorability scores. You will notice that ResMemRetrain’s predictions “clip” below 0.411. In other words, for the bottom ~0.5% of images, the model predicts their memorability as 0.411. This phenomenon comes from limited data in the low-memorability region and the mathematical nature of the memorability score. Even expanding the low memorability region to below 0.5, it still only contains 3% of our images.
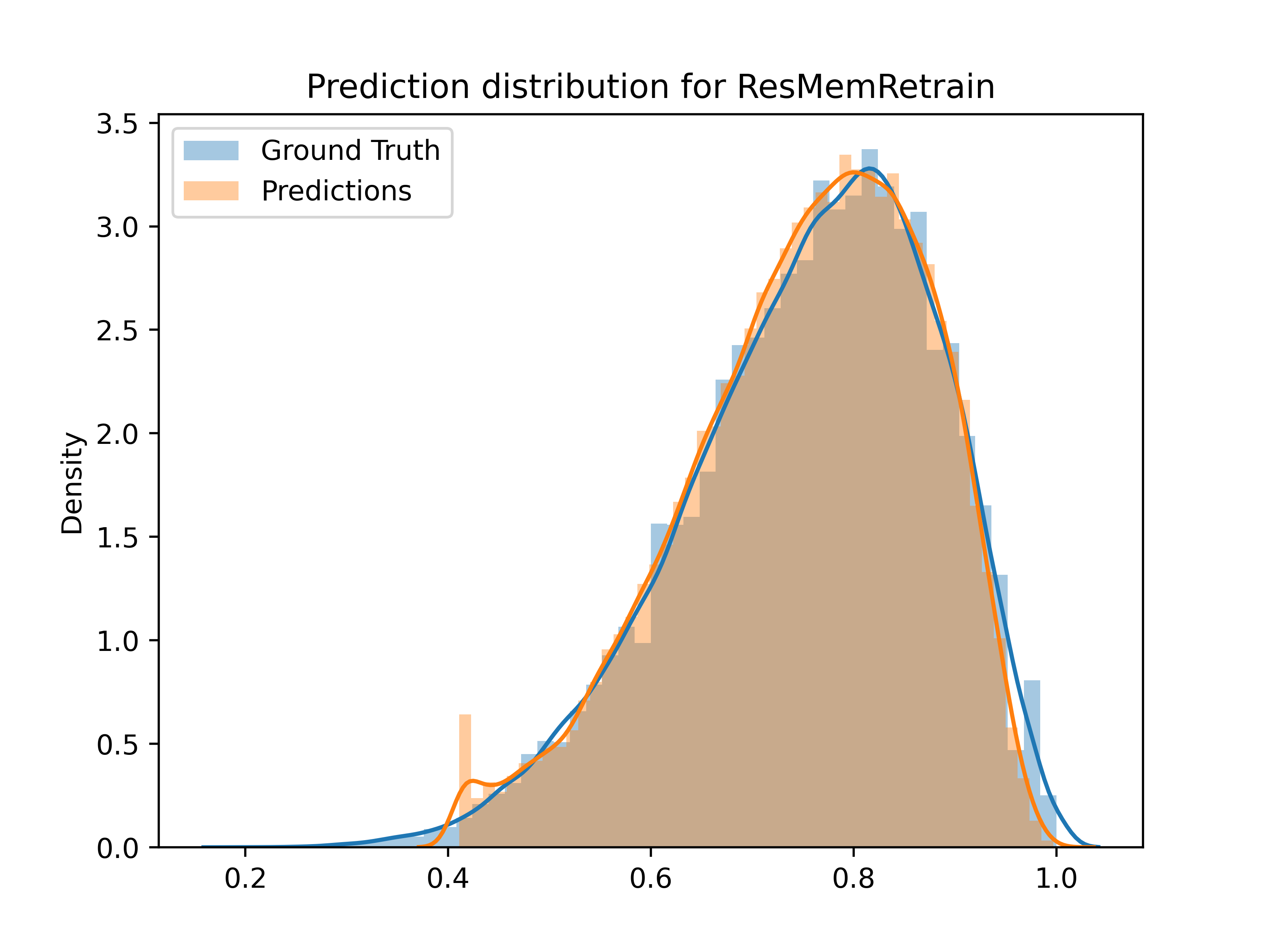
Because these ultra-low memorability images are rare, and we have such little data on them, even a deep learning model like ResMemRetrain struggles to predict their memorability accurately. Considering only images with measured memorability above 0.5, which is roughly 97% of images across LaMem and MemCat, the average inaccuracy falls to 0.05.
In addition, I would caution against using this model as pretrained on images of faces. It’s believed that face-memorability is a different problem than scene and object memorability. Using this architecture, and Wilma Bainbridge’s FACES database3, I’ve been able to make a model with rank correlations on the order of 0.2. In other words, it beats previous models, but not by a lot.
For more information on this project at-large, see the project page here.
Khosla, Aditya, Akhil S. Raju, Antonio Torralba, and Aude Oliva. 2015. “Understanding and Predicting Image Memorability at a Large Scale.” In2015 Ieee International Conference on Computer Vision (Iccv), 2390–8. IEEE.https://doi.org/10.1109/ICCV.2015.275.1 ↩︎
Goetschalckx, Lore, and Johan Wagemans. 2019. “MemCat: A New Category-Based Image Set Quantified on Memorability.” PeerJ 7 (December): e8169. https://doi.org/10.7717/peerj.8169. ↩︎
Bainbridge, Wilma A., Phillip Isola, and Aude Oliva. 2013. “The Intrinsic Memorability of Face Photographs.” Journal of Experimental Psychology: General 142 (4): 1323–34. https://doi.org/10.1037/a0033872. ↩︎